简单但是代码“说不清”的功能,不如让AI来实现! 场景 想象你是一个售卖软件激活码的商家,在收款后把激活码通过邮件的方式发送到客户的邮箱里,你的美好生活就这样一单一单地继续着。
直到有一天,你的好朋友说他给你介绍了个大生意,有几百个客户要从你这里购买软件,他给你发来了几张手写下来的便签照片 、几段格式杂乱的文本 ,上面记录了你所需要的信息:用户的名字和邮箱。
在你被迫转行干这个之前,你是个程序员,你给自己开发了个录入客户信息自动发货的系统。可是,这几百单要是一单一单录入的话要花很久。你摩拳擦掌地拿起ocr、正则表达式准备将这个苦差事自动化时,问题出现了:
ocr解析从图片里解析出来的文本还是乱糟糟的,错别字、无关的字符…显然ocr并不知道它要处理的是人名和邮箱,它只管识别图片里的字符,有一个算一个!
记录客户信息的文本,有的前面有序号,有的没有,有的用逗号作为分隔符,有的用句号,有的人名和邮箱分开了两行…本来你的正则就是上网抄的水平,如何用正则匹配格式这么灵活的文本真让你犯了难
幸运的是,在2024年,AI已经足够聪明来解决这样的问题。
我将用上面的例子介绍我是如何在一个CRUD的小项目中使用AI实现这种简单却灵活的功能的。示例工程使用了jdk21 + springboot3,你可能会看到一些新的api,例如虚拟线程和有序集合,请放心,这不是必需的,稍微变更一下写法也可以达到目的。
模型选择 openai推出的chatgpt是大模型领域堪称规则制定者的产品,后来的大模型产品例如kimi、通义千问在产品形式上都大量借鉴了openai的规范,例如长得差不多的对话网页、按token计价的计价方式、流式输出、类似的api。
切换不同的大模型提供商,你的代码几乎不需要做改动,只需要修改api key、base url、模型名字就可以了,编码成本并无区别。因此在模型选择上,你只需要关注模型对问题的回答效果、价格即可。我最终选择了kimi 。
怎么调用AI接口? 由于我的后端使用Java写的,我又不想按照官网的api文档拼http请求,我最终选择了jvm-openai ,一个厂商无关的、轻量级的sdk。(这个库要求jdk17+,如果你使用老版本jdk,可以使用OpenAI-Java ,这些sdk都遵循同一套规范,用起来差异并不大)
官网给了一个简单的示例,演示了如何通过sdk和AI做一次对话。
1 2 3 4 5 6 7 8 9 10 11 12 OpenAI openAI = OpenAI.newBuilder(System.getenv("OPENAI_API_KEY" )).build();ChatClient chatClient = openAI.chatClient();CreateChatCompletionRequest createChatCompletionRequest = CreateChatCompletionRequest.newBuilder() .model(OpenAIModel.GPT_3_5_TURBO) .message(ChatMessage.userMessage("Who won the world series in 2020?" )) .build(); ChatCompletion chatCompletion = chatClient.createChatCompletion(createChatCompletionRequest);
可以把你的模型api key、base url和模型的名字入参,试一试能不能正常收到AI的回答。
我们先看更简单的文本解析。在这个场景下,我们应该告诉AI我们的要求、要解析的文本数据,一次请求包含两条内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 OpenAI openAI = OpenAI.newBuilder(apiKey) .baseUrl(baseUrl) .build(); ChatClient chatClient = openAI.chatClient();ChatMessage.UserMessage.UserMessageWithTextContent promotContent = ChatMessage.userMessage(""" 识别出这个文本内容中所有的人名和邮箱,使用如下格式逐行输出解析结果: 姓名1 邮箱1 姓名2 邮箱2 ... """ ); ChatMessage.UserMessage.UserMessageWithTextContent textContent = ChatMessage.userMessage(text); CreateChatCompletionRequest createChatCompletionRequest = CreateChatCompletionRequest.newBuilder() .model(model) .messages(Arrays.asList(promotContent, textContent)) .build(); ChatCompletion chatCompletion = chatClient.createChatCompletion(createChatCompletionRequest);log.info("AI返回的结果:{}" , chatCompletion.choices().getFirst().message().content());
几秒后,你应该能得到AI的回答,它以非常整齐的格式返回了你需要的信息。
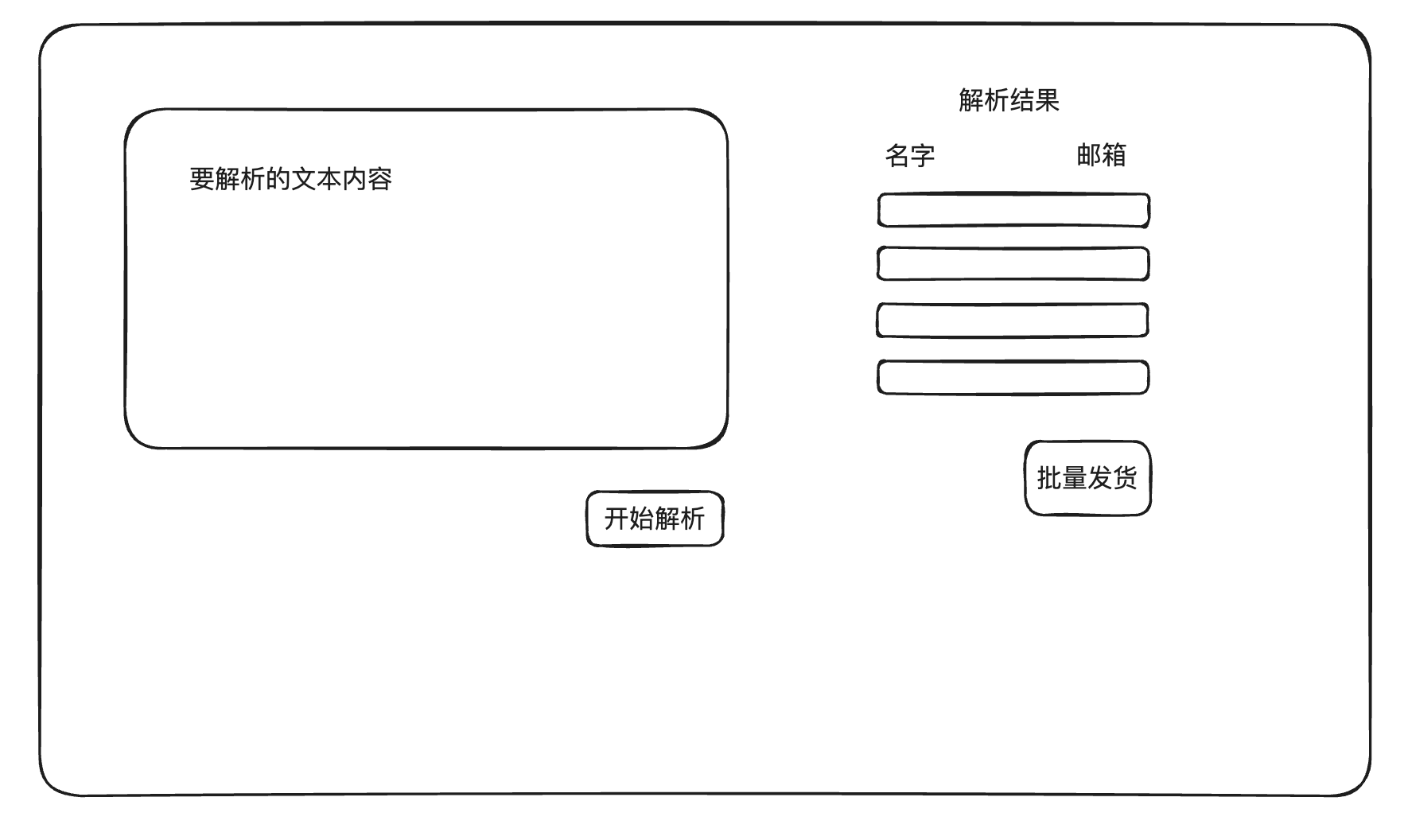
流式返回 你非常高兴,迅速发挥你的老本行优势,搭了一个前端页面:
这样,你就可以预览并修正AI可能产生的小错误,然后批量给这些用户发货。
但是,你发现解析的耗时相当久,一个请求可能会花费十几秒的时间,要不是因为这是你自己开发的系统,你肯定会刷新重试了。
chatgpt的解决方式是“流式返回”(stream),AI并不会憋个十几秒才给你返回结果,而是几个字符几个字符地返回,让前端的用户能看到它在正常运行。
把代码改成下面这样就可以了:
1 2 3 4 5 6 7 8 9 10 11 CreateChatCompletionRequest createChatCompletionRequest = CreateChatCompletionRequest.newBuilder() .model(model) .messages(Arrays.asList(promotContent, textContent)) .stream(true ) .build(); chatClient.streamChatCompletion(createChatCompletionRequest) .forEach(chatCompletion -> { String content = chatCompletion.choices().getFirst().delta().content(); log.info("AI返回的内容:{}" , content); });
我们发现AI开始几个字符几个字符地返回了,我们可以用StringBuilder作为缓冲区,每收集到一个完整的客户数据就打印一次:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 StringBuilder stringBuilder = new StringBuilder ();chatClient.streamChatCompletion(createChatCompletionRequest) .forEach(chatCompletion -> { String content = chatCompletion.choices().getFirst().delta().content(); log.info("AI返回的内容:{}" , content); if (content != null ) { stringBuilder.append(content); } if ("\n" .equals(content) || content == null ) { String[] split = stringBuilder.toString().split(" " ); String name = split[0 ].trim(); String email = split[1 ].trim(); log.info("名字:{}" , name); log.info("邮箱:{}" , email); stringBuilder.setLength(0 ); } });
那么,我们该怎么把这一段一段的数据发送到前端呢?
server-sent events server-sent events,简称sse,是一种后端主动向前端推送数据的技术,相较于双向通信的websocket,sse更简单,后端可以用类似编写一个get请求接口的方式实现一个sse接口,只不过返回值是一个SseEmitter对象。
1 2 3 4 5 @GetMapping("/batch-parse-by-text") @Operation(description = "根据文本批量解析客户名字和邮箱") public SseEmitter batchParseByText (@RequestParam String text) { return clientService.batchParseByText(text); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public SseEmitter batchParseByText (String text) { log.info("收到的文本:{}" , text); ChatClient chatClient = openAI.chatClient(); ChatMessage.UserMessage.UserMessageWithTextContent promotContent = ChatMessage.userMessage(""" 识别出这个文本内容中所有的人名和邮箱,使用如下格式逐行输出解析结果: 姓名1 邮箱1 姓名2 邮箱2 ... """ ); ChatMessage.UserMessage.UserMessageWithTextContent textContent = ChatMessage.userMessage(text); CreateChatCompletionRequest createChatCompletionRequest = CreateChatCompletionRequest.newBuilder() .model("moonshot-v1-auto" ) .messages(Arrays.asList(promotContent, textContent)) .stream(true ) .build(); SseEmitter sseEmitter = new SseEmitter ((long ) (1000 * 60 * 3 )); Thread.startVirtualThread(() -> { StringBuilder stringBuilder = new StringBuilder (); chatClient.streamChatCompletion(createChatCompletionRequest) .forEach(chatCompletion -> { String content = chatCompletion.choices().getFirst().delta().content(); log.info("AI返回的内容:{}" , content); if (content != null ) { stringBuilder.append(content); } if ("\n" .equals(content) || content == null ) { String[] split = stringBuilder.toString().split(" " ); String name = split[0 ].trim(); String email = split[1 ].trim(); ClientInfo clientInfo = ClientInfo.builder() .name(name) .email(email) .build(); try { sseEmitter.send(objectMapper.writeValueAsString(clientInfo)); } catch (IOException e) { log.error("发送SSE消息失败" , e); } } }); sseEmitter.complete(); }); return sseEmitter; }
尽管jvm-openai提供了基于CompletableFuture的异步接口,我还是选择新开一个虚拟线程去执行阻塞式方法,因为我觉得这样更易于理解和调试。
前端就更简单了,只需要建立连接、监听事件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 const sse = new EventSource (你的sse接口url以及必要参数)clients.splice (0 , clients.length ) sse.onmessage = (event : MessageEvent { const parseResult = JSON .parse (event.data ) clients.push ({ name : parseResult.name , email : parseResult.email }) } sse.onerror = () => { sse.close () }
这样,在开始解析后,我们很快就看到了后端陆陆续续传送来的数据。
图片解析 走完文本解析的全流程后,图片解析就很简单了,只需要修改几行代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 File imgFile = xxxFilesClient filesClient = openAI.filesClient();UploadFileRequest uploadInputFileRequest = UploadFileRequest.newBuilder() .file(imgFile.toPath()) .purpose("file-extract" ) .build(); io.github.stefanbratanov.jvm.openai.File inputFile = filesClient.uploadFile(uploadInputFileRequest); byte [] fileContent = filesClient.retrieveFileContent(inputFile.id());ChatClient chatClient = openAI.chatClient();ChatMessage.UserMessage.UserMessageWithTextContent promotContent = ChatMessage.userMessage(""" 识别出这个文本内容中所有的人名和邮箱,使用如下格式逐行输出解析结果: 姓名1 邮箱1 姓名2 邮箱2 ... """ );ChatMessage.UserMessage.UserMessageWithTextContent imgContent = ChatMessage.userMessage(new String (fileContent)); CreateChatCompletionRequest createChatCompletionRequest = CreateChatCompletionRequest.newBuilder() .model("moonshot-v1-auto" ) .messages(Arrays.asList(promotContent, imgContent)) .stream(true ) .build();
总结 本文通过解析格式不整齐的数据的例子,演示了如何使用AI实现一些简单但是灵活的功能,落实到了前后端代码。
有趣的是,本文封面原本是我拍的竖屏照片,但是用AI扩图扩成了适合做封面的横图,这也是我第一个AI处理过的文章封面。这种工作放在2023年之前肯定是要花点时间成本的,但是AI让我以极低的成本实现了这一点。